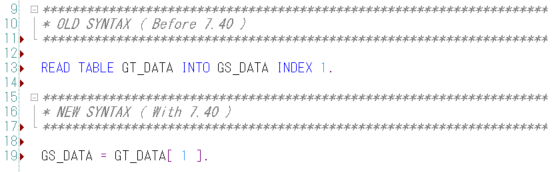
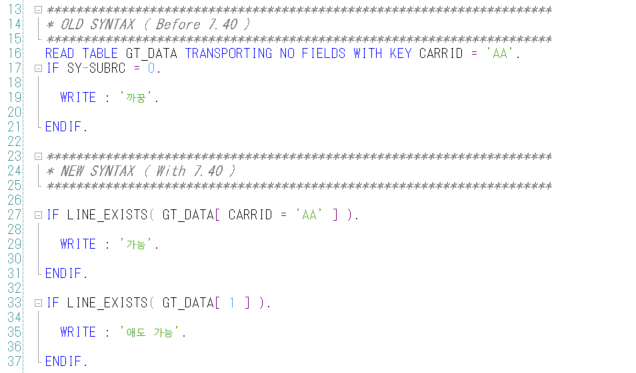
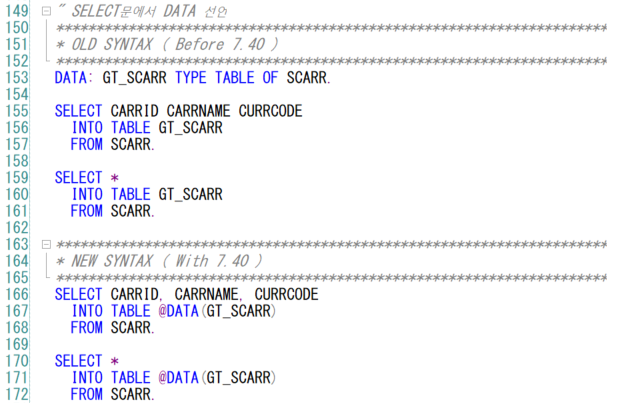
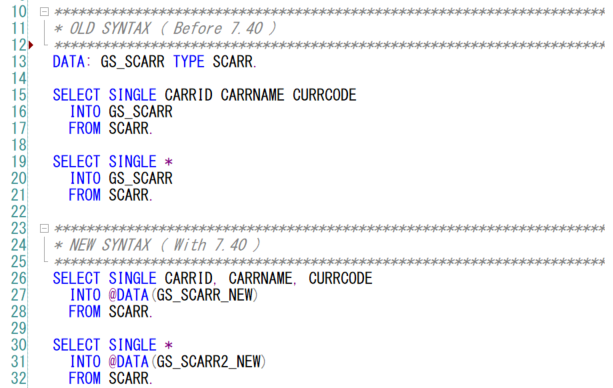
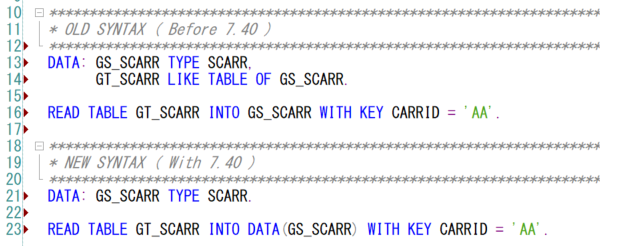
CONV란?
CONV 연산자는 데이터 타입을 변환하는데 사용된다.
한 타입의 변수를 다른 타입으로 변환할 수 있다.
CONV type( [let_exp] dobj ) 형식으로 사용되며, 아래와 같이 사용할 수 있다.
CONV #(
CONV I(
CONV STRING(
내가 느낀 것은 인라인 선언과 함께 사용할 때나, CLASS 나 FUNCTION의 파라미터를 입력할 때 편하다고 느꼈다.
예제를 통해서 하나씩 봐보자.
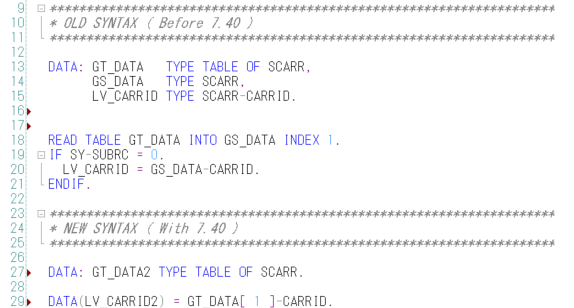
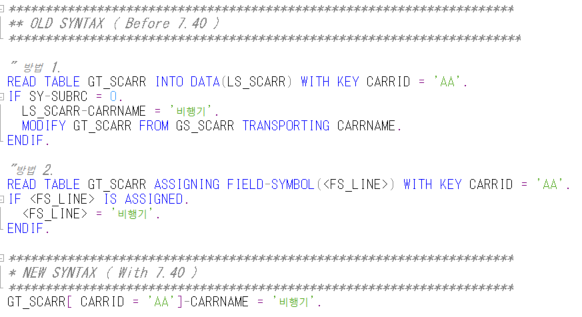
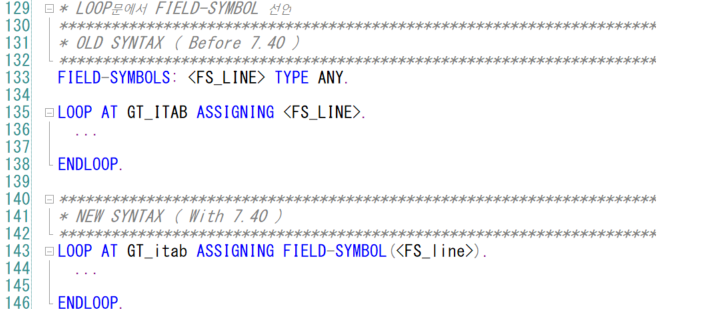
1. TYPE 변환
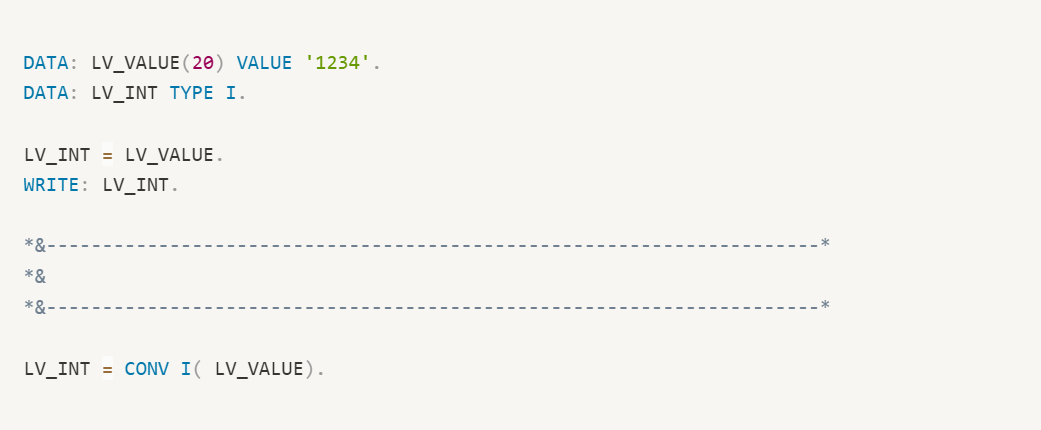
두 가지 타입이 다른 경우가 있다.
LV_VALUE는 TYPE C 이고 LV_INT는 TYPE I 이다.
CONV 연산자는 데이터의 TYPE을 변환해준다.
해당 코드는 LV_VALUE의 값을 TYPE 'I' 로 변환해 LV_INT에 할당하라는 코드이다.
실제 프로그램에서는 CHAR 와 INT 타입은 SAP 스탠다드 설정으로 자동 변환되어 CONV를 사용하지 않아도 정상적으로 실행된다.
저렇게 사용한다는 것만 참고하자.
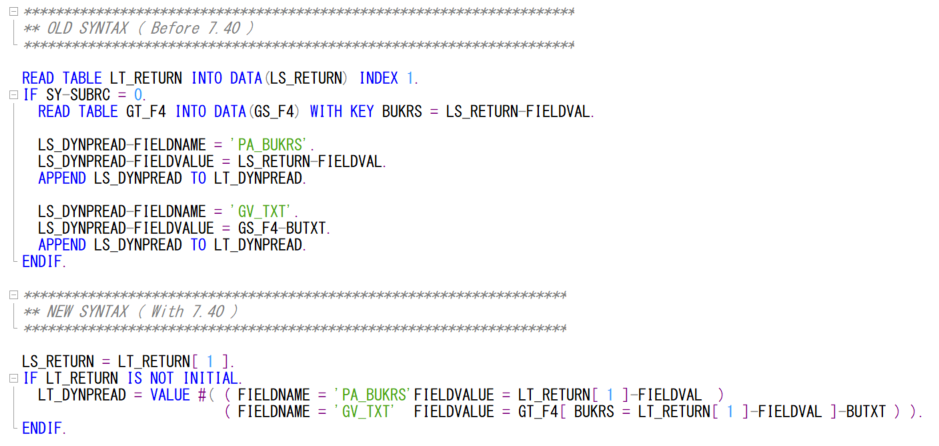
2. FUNCTION 에서 사용
- CONV는 TYPE 변환 연산자라고 했다. 우리가 TYPE 변환을 많이 사용하는 FUNCTION MODULE에서의 사용법이다.

해당 FUNCTION은 DAY_IN이라는 파라미터가 날짜타입이다. 우리는 여기에 문자형을 넣을거다.
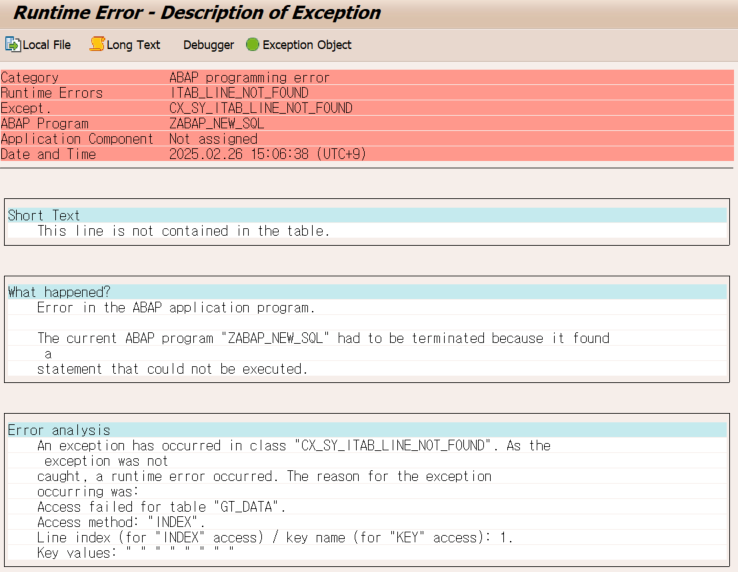
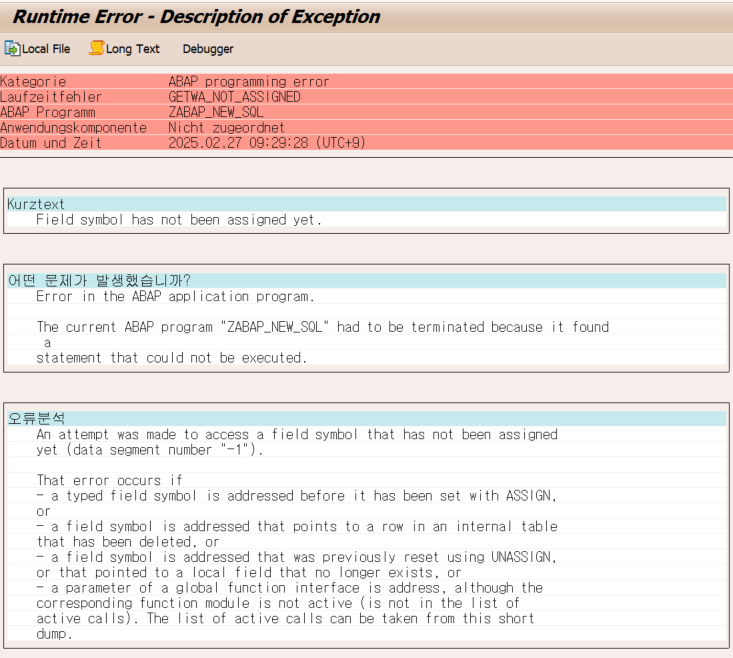
그러면 당연히 파라미터와 TYPE이 맞지 않아 덤프가 뜰거다.
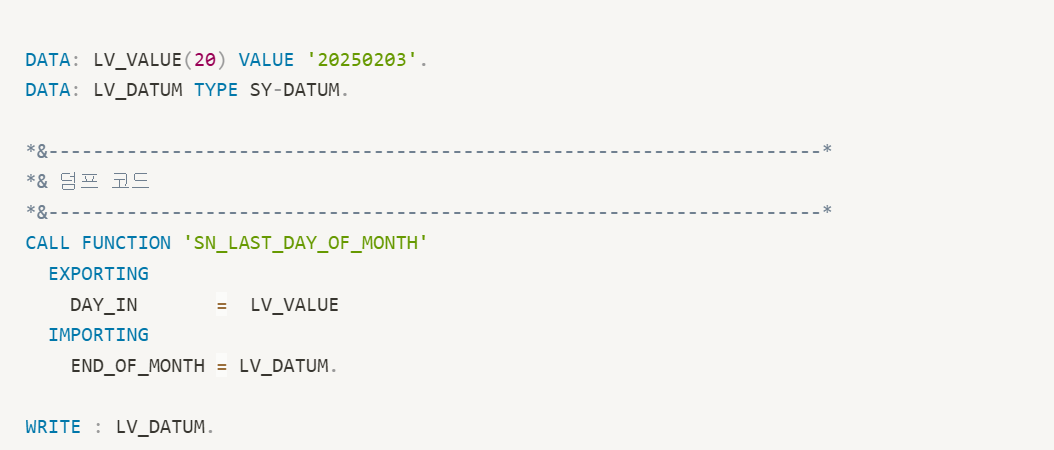
위의 코드는 TYPE 불일치로 덤프가 나오는 코드이다.
나는 과거에 교육 과정 프로젝트에서 TYPE 생각을 안하다가 덤프를 마주한적이 간혹 있었다.
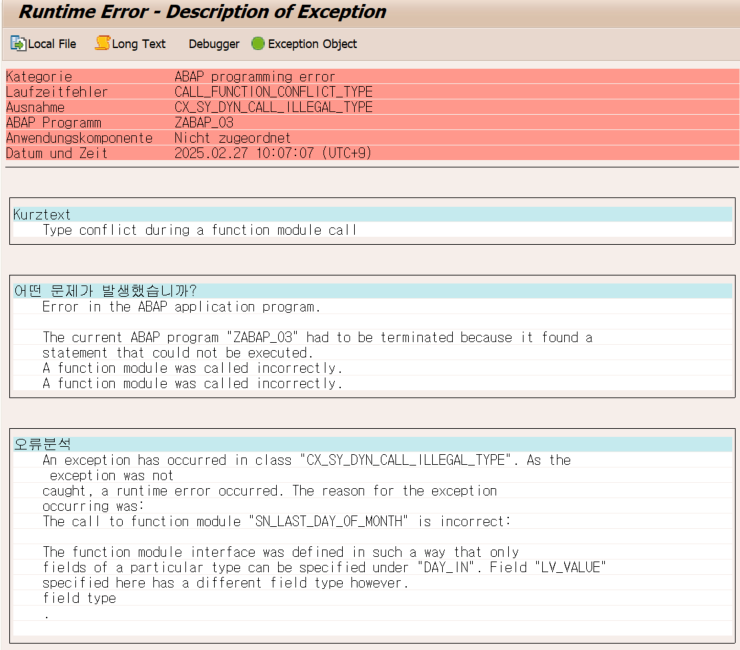
Function Module의 파라미터와 변수가 TYPE이 맞지 않아 덤프가 뜬다.

이럴 때마다 나는 해당 TYPE에 맞는 변수를 새로 생성해주고 TYPE을 변환시켰었다. (근데 이게 은근 귀찮다....)
하지만 이제는! CONV를 써서 간편하게 TYPE을 변환할 수 있다.

CONV 연산자를 사용해 LV_VALUE를 TYPE D로 변환하는 코드이다.
근데 여기서도 한가지 의문이 생겼다.
대부분 CONV 연산자에 예시로 TYPE I, TYPE STRING 등만 있어서
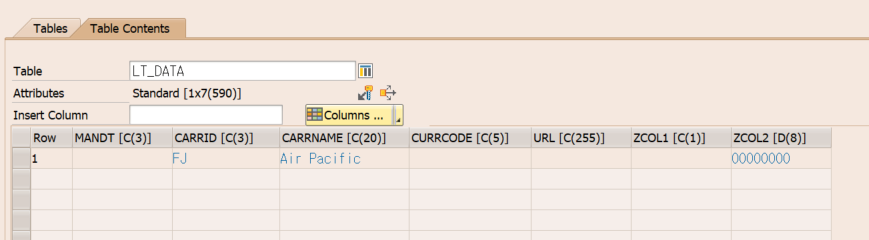
CONV SFLIFHT-FLDATE (LV_VALUE) 처럼 TABLE의 필드도 사용되는지 궁금했다.

정상적으로 프로그램이 실행되고 LV_VALUE가 BKPF 테이블의 BLDAT TYPE으로 변환된다.
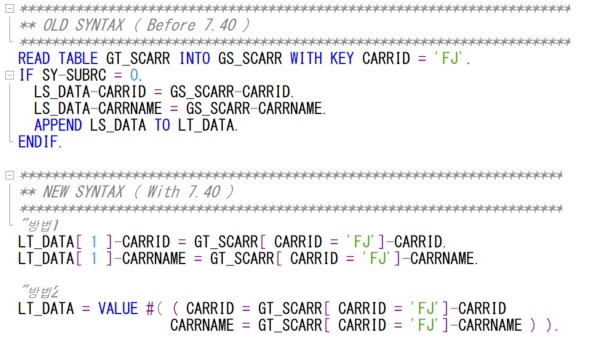
3. CLASS
만약에 아래와 같은 클래스가 있다고 치자.

I_INT1과 I_INT2는 I 타입이다.
만약 LV_F가 F 타입이기 때문에 CONV 없이 그냥 들어간다면 FUNCTION 때 처럼 덤프가 발생할 거다.
하지만 CONV # 을 사용하면은 CLASS의 파라미터 타입으로 변환되어 덤프가 뜨지 않는다.
그러면 여기서 CLASS의 CONV # 과 FUNCTION의 CONV랑 차이가 궁금할거다.
CONV #
- CLASS에서만 사용 가능
- 자동적으로 파라미터의 TYPE을 받아준다 ( VALUE # 과 동일 )
CONV TYPE
- Function 에서 사용 시, CONV 뒤에 타입을 꼭 지정해줘야 한다. (CONV # 불가능 )
- TABLE의 Field로도 TYPE을 받을 수 있다.
만약에 왜 CLASS에서는 #이되고, Function에서는 #이 안되는 지 궁금하다면,
내가 이전의 데이터 인라인 선언 게시글에 정리하였으니, 그거를 참고하면 된다!
# 데이터 인라신 선언 포스팅 참고!
2025.03.05 - [SAP/NEW SYNTAX] - [SAP ABAP] NEW SYNTAX # - 데이터 인라인 선언( Inline Declarations )
[SAP ABAP] NEW SYNTAX # - 데이터 인라인 선언( Inline Declarations )
SAP의 ERP 시스템은 방대한 데이터를 효율적으로 관리하는 것이 핵심이다. 기존 ABAP Old SYNTAX는 오랫동안 사용되어 왔지만, 대량의 데이터를 처리할 때 성능 문제와 제한 사항이 존재했었다. 그러
roblige.tistory.com
4. 응용 방법
1) TABLE의 라인 수를 이용하여, 메세지 출력 또는 TITLE 에 사용

2) CLASS에서 사용

해당 응용 방법 말고도 많은 방법이 존재하니, 잘 활용하기를 바란다.
오늘도 파이팅 입니다. :)
'SAP > NEW SYNTAX' 카테고리의 다른 글
| [SAP ABAP] NEW SYNTAX #2 - 테이블 표현식(Table Expressions) (0) | 2025.03.07 |
|---|---|
| [SAP ABAP] NEW SYNTAX # - 데이터 인라인 선언( Inline Declarations ) (1) | 2025.03.05 |